Relearning Variational Inference
The other day, I realized that there’s a lot of content covered in MIT’s machine learning classes (6.867, 9.520) that I still don’t understand thoroughly, despite having taken these classes. So, this will be the first post in a hopefully long series where I take notes on materials I review.
Please be aware that a lot of the content covered in this post is taken from here.
The Problem
We want to construct a generative model which can deal with latent variables. What does this mean?
A generative model is a model which, given data, tries to learn the probabilistic distribution from which the data is generated. For example, a model that tries to learn the parameters of a Gaussian distribution from data would be a generative model. Other examples of generative models include Hidden Markov Models or Latent Dirichlet Allocation.
On the other hand, discriminative models, such as a linear classifier, attempt to directly solve problems such as classification or prediction without learning the data distribution. In a supervised learning setting with data points , generative models can be thought of as learning the distribution , while discriminative models learn .
Latent variables, as Wikipedia explains, are “variables which that are not directly observed but rather inferred (through a mathematical model) from other variables that are observed (directly measured).” For example, consider the Gaussian mixture model below:
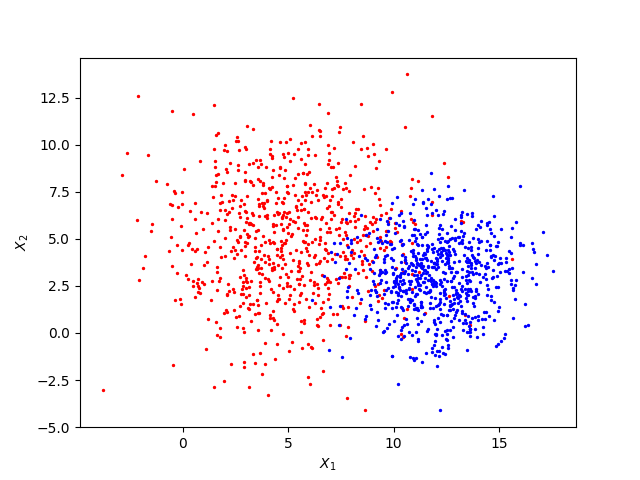
Here, the distribution of points is drawn from Gaussian 1 with and with probability , and from Gaussian 2 with and with the remaining probability. In this example, the only two observed variables are the dimensions of the figure, and . On the other hand, the , and variables of each Gaussian are all latent variables. Although we can’t observe these parameters directly from the figure, they affect the distribution and we can infer them from the figure to some extent. Also note that the probability of a point being drawn from either Gaussian, in this case , is also a latent variable.
Circling back to our original problem statement, we want to construct a “model which learns the distribution of data” that can deal with “variables which we can’t observe directly, but affect the distribution and can be inferred.” For the remainder of this post, we will use the conventional notation to denote observed variables, and to denote latent variables.
Computing the Posterior
Let denote the set of hyperparameters which we manually specify to determine the conditions from which the latent variables are generated. We’re interested in the posterior distribution:
The posterior distribution is useful because it’s essentially is a formalization what we want: given a set of observations, we want to learn and make inferences on the latent variables. By learning these latent variables, we’d be able to construct our desired generative model and learn the distribution from which is generated from.
Unfortunately, the posterior isn’t directly computable for a lot of distributions. Consider the following (Bayesian Mixture of Gaussians), taken from here:
- Generate from .
-
For :
a. Generate from .
b. Generate from .
In this example, we have the hyperparameters . Our latent variables consist of , and . This is pretty similar to the mixture of Gaussians that we had previously – we just specified the distribution from which is generated, and fixed .
We have that . Equivalently, this equals
Consider the denominator of the posterior:
This expression is not easy to evaluate. We can try to move the summation inside of the product:
The term is a product of sums of Gaussian probabilities , and as far as I know there’s no reasonable way to simplify the inside expression of the integral into a closed-form expression. If we try multiplying out the inner product, we’ll get individual terms, which isn’t computationally viable. We can also try moving the summation outside:
Now the inside of the integral is computable, but we again have the problem of individual terms. So, we conclude that directly evaluating the exact posterior distribution is computationally intractable.
Variational Inference
Now here is the part where variational inference comes in. We resign ourselves to the fact that we can’t directly compute the posterior , and instead select a family of distributions
with variational parameters . The goal of variational inference is to determine such that best approximates the original posterior . Here you may have a couple of questions:
- What would you select for a family of distributions ?
- We’ll get to this later (see Mean-field variational inference).
- What do you mean exactly by “best approximates”?
- Yes, we need a formal measure of how well a distribution resembles another. This leads us to…
Kullback-Leibler Divergence
Frequently called KL-divergence, Kullback-Leibler divergence allows us to measure to what extent one probability distribution diverges from another:
Qualitatively, when optimizing for KL-divergence we just want to avoid cases when is high and is low. When is low, the corresponding cost is also low since the cost is proportional to . When both and are high, then the corresponding cost is low as long as the two probabilities are of approximately the same magnitude.
It’s worth noting that KL-divergence is not symmetric: does not necessarily equal . We purposely choose to use . We’ll later have to evaluate some expectations – since we’re able to compute but not , it’ll be easier to work with , which takes expectations relative to . While there’s a form of variational inference which uses called expectation propagation, I’m not too familiar with it and won’t be covered in this post.
Evidence Lower Bound
Turns out, KL-divergence is difficult to directly minimize because the posterior still gives us trouble. We’ll use a nice trick called the evidence lower bound (ELBO) to get around this. From some nice math, we have:
The expression is the evidence lower bound. The term does not depend on or the variational parameters . As a result, maximizing the ELBO results in minimizing the KL-divergence. (If you’re interested, ELBO gets its name because it serves as a lower bound for . From this fact, it follows that KL-divergence is always non-negative.)
Summary
To recap, variational inference is a means for learning latent variables from the posterior distribution . Because the posterior is often difficult to compute, we resort to finding a similar distribution . By finding variational parameters which maximize the ELBO , we also minimize KL-divergence and find the distribution which best approximates the posterior.
In the next post, I’ll talk about mean-field variational inference, a specific instance of variational inference which places restrictions on and provides a way to maximize the ELBO.
References
- https://www.cs.princeton.edu/courses/archive/fall11/cos597C/lectures/variational-inference-i.pdf.
- https://www.quora.com/What-is-variational-inference. I liked Sam Wang’s summary: “In short, variational inference is akin to what happens at every presentation you’ve attended. Someone in the audience asks the presenter a very difficult answer which he/she can’t answer. The presenter conveniently reframes the question in an easier manner and gives an exact answer to that reformulated question rather than answering the original difficult question.”